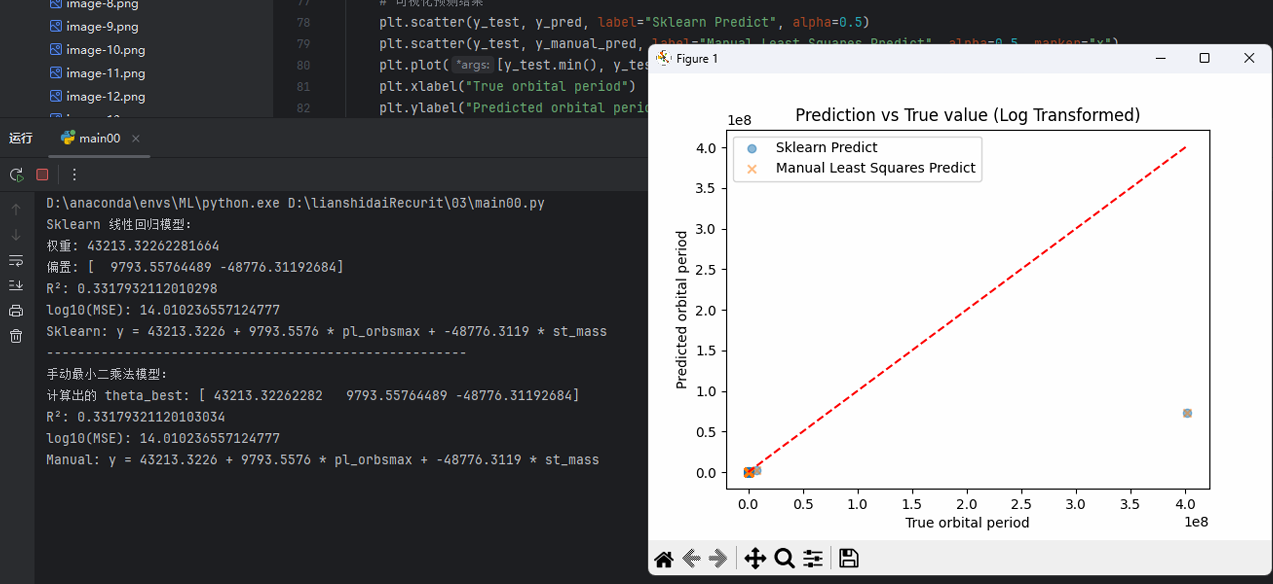
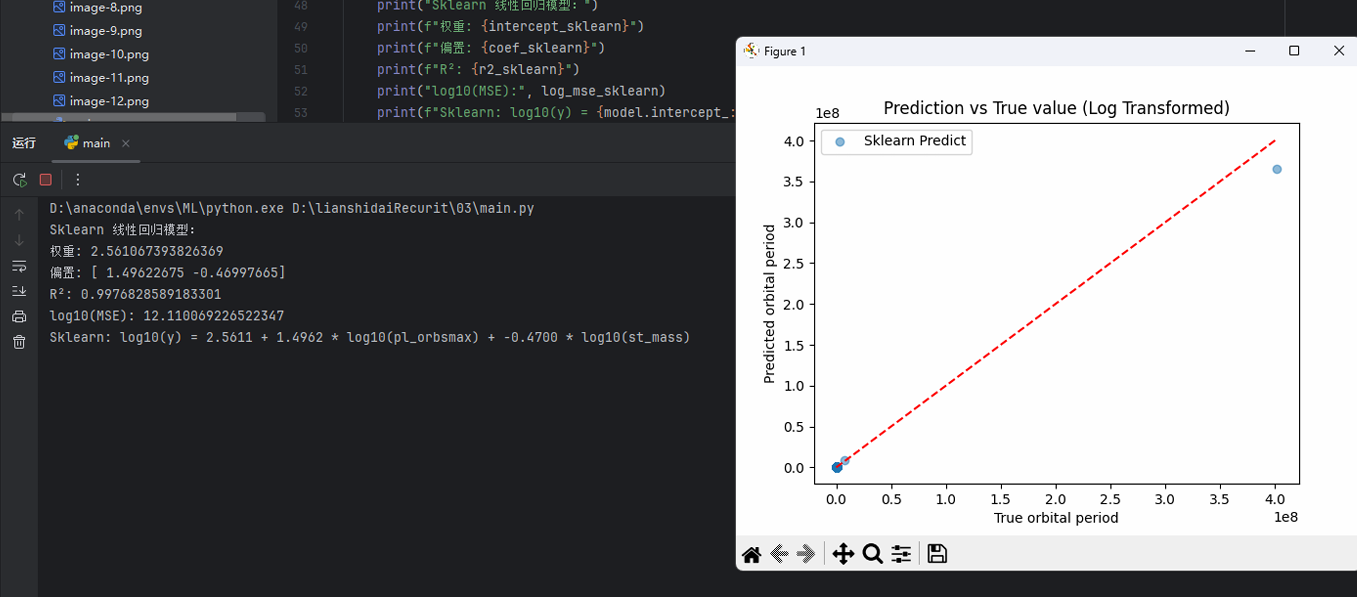
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
| import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim.lr_scheduler import OneCycleLR
from torchtext.datasets import IMDB
from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator
from torch.utils.data import DataLoader, Dataset
import matplotlib.pyplot as plt
import numpy as np
tokenizer = get_tokenizer("spacy", language="en_core_web_sm")
def collect_tokens(data_iter):
"""
:param data_iter: IMDB数据集
:return: 返回单词列表
"""
all_tokens = []
for _, text in data_iter:
tokens = tokenizer(text)
all_tokens.append(tokens)
return all_tokens
train_iter = IMDB(split="train")
test_iter = IMDB(split="test")
vocab = build_vocab_from_iterator(collect_tokens(train_iter), max_tokens=20000, specials=["<pad>", "<unk>"])
vocab.set_default_index(vocab["<unk>"])
def text_pipeline(text):
"""
:param text: 欲处理的文本列表
:return: 文本对应的索引列表
"""
tokens = tokenizer(text)
max_length = 100
tokens = tokens[:max_length]
index = []
for token in tokens:
index.append(vocab[token])
return index
def label_pipeline(label):
"""
:param label: 情感标签 pos 或 neg
:return: 将 pos 或 neg 映射为 1 或 0
"""
return 1 if label == "pos" else 0
class IMDBDataset(Dataset):
"""自定义 IMDB 数据集类,用于加载 IMDB 电影评论数据"""
def __init__(self, data_iter):
"""
初始化
:param data_iter: 同时包含 (label,text) 的数据迭代器
"""
self.data = []
for label, text in data_iter:
self.data.append((text_pipeline(text), label_pipeline(label)))
def __len__(self):
"""
:return: 返回数据集 self.data 长度
"""
return len(self.data)
def __getitem__(self, idx):
"""
:param idx: 索引
:return: 索引对应的单词
"""
return self.data[idx]
train_data = IMDBDataset(train_iter)
test_data = IMDBDataset(test_iter)
def collate_fn(batch):
"""
处理批量数据,对文本进行填充使其长度一致
:param batch: 批量数据
:return: 填充处理之后的结果
"""
texts, labels = zip(*batch)
lengths = []
for text in texts:
lengths.append(len(text))
max_len = max(lengths)
padded_texts = []
for text in texts:
padded_texts.append(text + [vocab["<pad>"]] * (max_len - len(text)))
return torch.tensor(padded_texts), torch.tensor(labels, dtype=torch.float)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
train_loader = DataLoader(train_data, batch_size=64, shuffle=True, collate_fn=collate_fn)
test_loader = DataLoader(test_data, batch_size=64, shuffle=False, collate_fn=collate_fn)
class PositionalEncoding(nn.Module):
""" 定义位置编码类,为 Transformer 提供位置信息 """
def __init__(self, d_model, dropout):
"""
:param d_model: 词向量的维度
:param dropout: Dropout 的概率,用于防止过拟合。
"""
super().__init__()
self.dropout = nn.Dropout(p=dropout)
max_len = 5000
position_code = torch.zeros(max_len, d_model)
position_item = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-np.log(10000.0) / d_model))
position_code[:, 0::2] = torch.sin(position_item * div_term)
position_code[:, 1::2] = torch.cos(position_item * div_term)
self.register_buffer('position_code', position_code)
def forward(self, x):
"""
前向传播
:param x: 输入张量 (batch_size, seq_len, d_model)
:return: 添加位置编码之后的张量
"""
x = x + self.position_code[:x.size(1)]
return self.dropout(x)
class TransformerClassifier(nn.Module):
""" 定义 Transformer 分类模型 """
def __init__(self, vocab_size, embed_dim, num_heads, num_layers, hidden_dim, dropout):
"""
初始化
:param vocab_size: 词汇表的大小
:param embed_dim: 词嵌入的维度
:param num_heads: Multi-Head 的头数
:param num_layers: Encoder 的层数
:param hidden_dim: FNN的隐藏层维度
:param dropout: dropout 率
"""
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.pos_encoder = PositionalEncoding(embed_dim, dropout)
encoder_layers = nn.TransformerEncoderLayer(d_model=embed_dim, nhead=num_heads, dim_feedforward=hidden_dim, dropout=dropout)
self.transformer_encoder = nn.TransformerEncoder(encoder_layers, num_layers)
self.fc = nn.Linear(embed_dim, 1)
self.dropout = nn.Dropout(dropout)
def forward(self, text):
"""
前向传播,完成计算流程
:param text: 输入的文本张量 形状为 (batch_size, seq_len)
:return:分类结果,形状为 (batch_size)
"""
embedded = self.embedding(text)
embedded = self.dropout(embedded)
embedded = self.pos_encoder(embedded)
embedded = embedded.transpose(0, 1)
output = self.transformer_encoder(embedded)
output = output.mean(dim=0)
return self.fc(output).squeeze(1)
embed_dim = 512
num_heads = 4
num_layers = 4
hidden_dim = 512
dropout = 0.2
epochs = 10
model = TransformerClassifier(
vocab_size=len(vocab),
embed_dim=embed_dim,
num_heads=num_heads,
num_layers=num_layers,
hidden_dim=hidden_dim,
dropout=dropout
).to(device)
optimizer = optim.AdamW(model.parameters(), lr=1e-4, weight_decay=1e-2)
scheduler = OneCycleLR(
optimizer,
max_lr=1e-4,
total_steps=epochs * len(train_loader),
pct_start=0.3,
anneal_strategy='cos',
div_factor=10,
final_div_factor=100
)
criterion = nn.BCEWithLogitsLoss().to(device)
def train(model, loader, optimizer, criterion, scheduler):
model.train()
epoch_loss = 0
for text, label in loader:
text, label = text.to(device), label.to(device)
predictions = model(text)
loss = criterion(predictions, label)
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
optimizer.step()
scheduler.step()
epoch_loss += loss.item()
return epoch_loss / len(loader)
def evaluate(model, loader, criterion):
model.eval()
epoch_loss = 0
correct, total = 0, 0
with torch.no_grad():
for text, label in loader:
text, label = text.to(device), label.to(device)
predictions = model(text)
loss = criterion(predictions, label)
epoch_loss += loss.item()
preds = torch.sigmoid(predictions) > 0.5
correct += (preds == label).sum().item()
total += label.size(0)
return epoch_loss / len(loader), correct / total
train_losses, test_losses, test_accs = [], [], []
for epoch in range(epochs):
train_loss = train(model, train_loader, optimizer, criterion, scheduler)
test_loss, test_acc = evaluate(model, test_loader, criterion)
train_losses.append(train_loss)
test_losses.append(test_loss)
test_accs.append(test_acc)
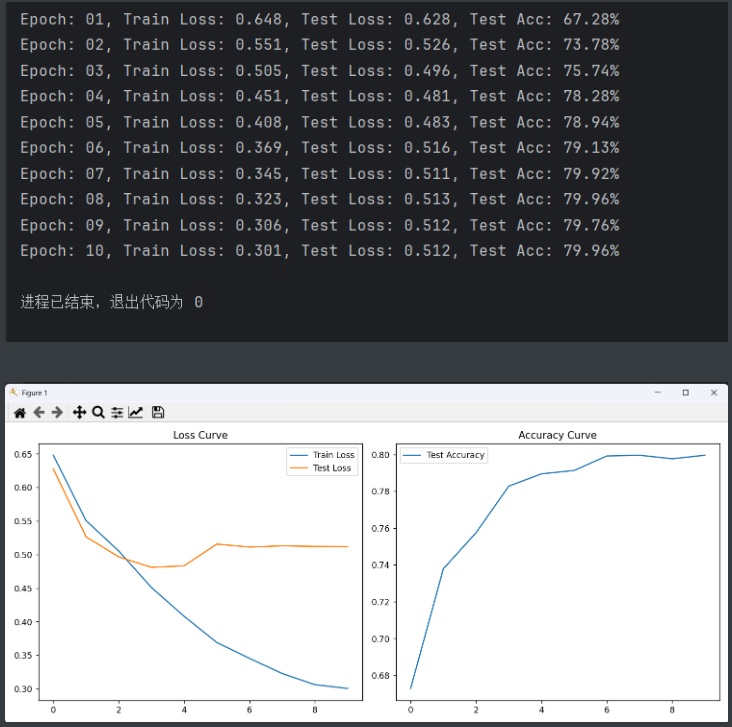
print(f'Epoch: {epoch + 1:02}, Train Loss: {train_loss:.3f}, Test Loss: {test_loss:.3f}, Test Acc: {test_acc:.2%}')
torch.save(model.state_dict(), "model.pth")
torch.save(vocab, "vocab.pth")
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(train_losses, label='Train Loss')
plt.plot(test_losses, label='Test Loss')
plt.legend()
plt.title('Loss Curve')
plt.subplot(1, 2, 2)
plt.plot(test_accs, label='Test Accuracy')
plt.legend()
plt.title('Accuracy Curve')
plt.tight_layout()
plt.show()
|