1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
| import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
from torch.optim.lr_scheduler import OneCycleLR
from transformers import BertTokenizer, BertForSequenceClassification
from torchtext.datasets import IMDB
import matplotlib.pyplot as plt
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
def text_pipeline(text):
"""
:param text: 原始文本
:return: 处理后的 token id 和 attention mask
"""
return tokenizer(text, padding="max_length", truncation=True, max_length=100, return_tensors="pt")
def label_pipeline(label):
"""
:param label: 电影评论标签(pos/neg)
:return: 1 表示正面,0 表示负面
"""
return 1 if label == "pos" else 0
class IMDBDataset(Dataset):
"""自定义 IMDB 数据集类"""
def __init__(self, data_iter):
"""
:param data_iter: IMDB 数据集迭代器
"""
self.data = []
for label, text in data_iter:
encoding = text_pipeline(text)
self.data.append((
encoding["input_ids"].squeeze(0),
encoding["attention_mask"].squeeze(0),
label_pipeline(label)
))
def __len__(self):
"""返回数据集大小"""
return len(self.data)
def __getitem__(self, idx):
"""获取数据集中的单个样本"""
return self.data[idx]
train_iter, test_iter = IMDB(split="train"), IMDB(split="test")
train_data, test_data = IMDBDataset(train_iter), IMDBDataset(test_iter)
def collate_fn(batch):
"""
处理批量数据
:param batch: 输入数据
:return: 处理后的 input_ids, attention_masks, labels
"""
input_ids, attention_masks, labels = zip(*batch)
return torch.stack(input_ids), torch.stack(attention_masks), torch.tensor(labels, dtype=torch.long)
train_loader = DataLoader(train_data, batch_size=64, shuffle=True, collate_fn=collate_fn)
test_loader = DataLoader(test_data, batch_size=64, shuffle=False, collate_fn=collate_fn)
model = BertForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=1).to(device)
for param in model.bert.encoder.layer[:-4].parameters():
param.requires_grad = False
optimizer = optim.AdamW(model.parameters(), lr=5e-5, weight_decay=1e-2)
criterion = nn.BCEWithLogitsLoss().to(device)
EPOCHS = 3
scheduler = OneCycleLR(
optimizer,
max_lr=5e-5,
total_steps=EPOCHS * len(train_loader),
pct_start=0.3,
anneal_strategy='cos',
div_factor=10,
final_div_factor=100
)
def train(model, loader, optimizer, criterion, scheduler):
model.train()
epoch_loss = 0
for input_ids, attention_masks, labels in loader:
input_ids, attention_masks, labels = input_ids.to(device), attention_masks.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(input_ids, attention_mask=attention_masks)
logits = outputs.logits.squeeze(1)
loss = criterion(logits, labels.float())
loss.backward()
optimizer.step()
scheduler.step()
epoch_loss += loss.item()
return epoch_loss / len(loader)
def evaluate(model, loader, criterion):
model.eval()
epoch_loss, correct, total = 0, 0, 0
with torch.no_grad():
for input_ids, attention_masks, labels in loader:
input_ids, attention_masks, labels = input_ids.to(device), attention_masks.to(device), labels.to(device)
outputs = model(input_ids, attention_mask=attention_masks)
logits = outputs.logits.squeeze(1)
loss = criterion(logits, labels.float())
epoch_loss += loss.item()
preds = torch.sigmoid(logits) > 0.5
correct += (preds == labels).sum().item()
total += labels.size(0)
return epoch_loss / len(loader), correct / total
train_losses, test_losses, test_accs = [], [], []
for epoch in range(EPOCHS):
train_loss = train(model, train_loader, optimizer, criterion, scheduler)
test_loss, test_acc = evaluate(model, test_loader, criterion)
train_losses.append(train_loss)
test_losses.append(test_loss)
test_accs.append(test_acc)
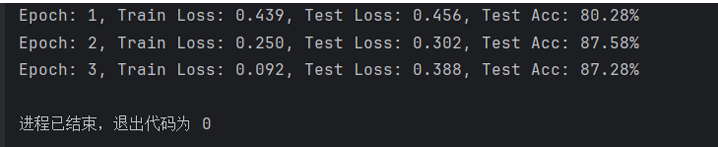
print(f'Epoch: {epoch + 1:02}, Train Loss: {train_loss:.3f}, Test Loss: {test_loss:.3f}, Test Acc: {test_acc:.2%}')
torch.save(model.state_dict(), "bert_imdb.pth")
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(train_losses, label="Train Loss")
plt.plot(test_losses, label="Test Loss")
plt.legend()
plt.title("Loss Curve")
plt.subplot(1, 2, 2)
plt.plot(test_accs, label="Test Accuracy")
plt.legend()
plt.title("Accuracy Curve")
plt.tight_layout()
plt.show()
|