任务
- 使用 NASA系外行星数据库 中的数据
- 选取轨道半长轴(pl_orbsmax)和母恒星质量(st_mass)作为输入特征
- 目标变量为轨道周期(pl_orbper)
思路
导入必要的库
1 | import numpy as np |
第一步: 访问 NASA 系外行星数据库,获取行星数据保存在 csv 文件中
第二步: 提取 csv 文件中所需要的数据,保留’pl_orbsmax’, ‘st_mass’和’pl_orbper’数据,与此同时注意到某些数据是缺失的,故而使用 df.dropna(subset=['pl_orbsmax', 'st_mass', 'pl_orbper']) 用来删除含有缺失值的数据组,保证后续计算正确
1 | # 加载数据 |
第三步: 使用提取到的数据来训练模型
首先需要将数据使用 train_test_split 来拆分成 8:2 的训练集和测试集,使用训练集来进行线性回归拟合
1 | # 拆分训练集和测试集 |
第四步: 使用 MSE、R检测法 来评估模型的预测性能
1 | # 预测 |
第五步: 手动使用最小二乘法来完成线性回归的任务,这里具体的计算方法使用了 伪逆矩阵
1 | def manual(X_train, X_test, y_train, y_test): |
第六步: 将预测值的真实值的关系使用 matplotlib 绘制散点图进行 可视化
1 | def draw_plot_map(): |
第七步: 输出最终的线性方程参数
1 | def output(): |
第八步: 对数据进行对数变换,然后重复第二到七步,获得模型效果,进行对比
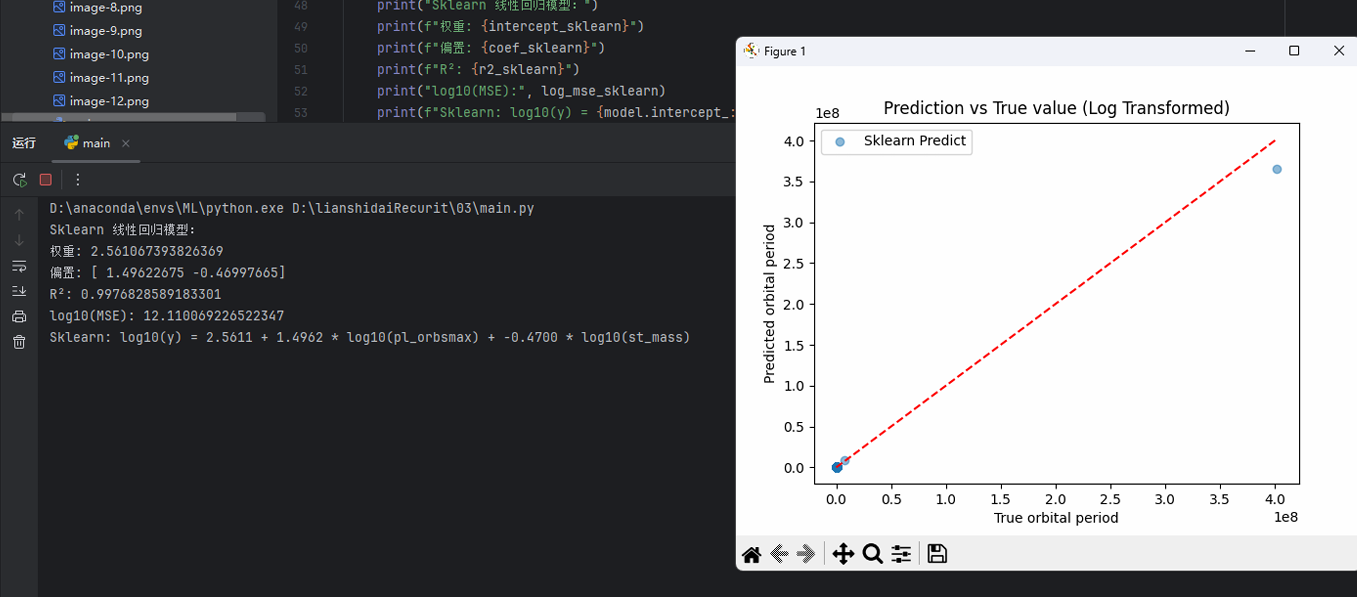
在 天体问题 中,习惯的对数变换是以 10为底数 的变换,更符合天文物理学的习惯。与此同时,取对数可以更直观地对应开普勒定律。
这里需要时刻注意何时使用 对数后的数据 何时使用 原数据
具体使用代码来实现如下:
1 | def pre(): |
第九步: 解释模型的误差
各个系数的物理含义:
回归方程:
[
\log_{10} pl_orbper = 2.5611 + 1.4962 \log_{10} pl_orbsmax - 0.4700 \log_{10} st_mass
]
对比理论的开普勒第三定律:
[
pl_orbper = C \cdot pl_orbsmax^{3/2} \cdot st_mass^{-1/2}
]
取对数:
[
\log_{10} pl_orbper = \log_{10} C + 1.5 \log_{10} pl_orbsmax - 0.5 \log_{10} st_mass
]
其中,偏置项 代表:
[
\log_{10} C
]
所以,我们可以反推:
[
C = 10^{2.5611} \approx 363
]
开普勒定律的系数 C 取决于单位, 在以 AU、天和太阳质量 为单位的时候, 理论值为365.25
而由公式可得,另两个参数的理论值应该分别为 1.5 和 -0.5
最终的参数 实际值 和 理论值 对比:
$363 \approx 365.25 $
$1.4962 \approx 1.5$
$-0.4700 \approx -0.5$
尽管各个系数非常接近 理论值,但不完全一致,可能有几个原因:
- 数据误差
- 测量数据可能有误差,导致拟合出的参数略有偏差
- 情况复杂
- 理论上行星轨道只受到半径和质量的影响,但是在现实情况下,会受到其他天体(附近的行星)的引力扰动,这使得产生了噪声
如果希望修复这问题,我有以下两个思路:
- 增大数据量
- 通过增大训练的数据量,可以一定程度上减少测量带来的误差影响
- 删除噪声过大的数据
- 对于某些行星而言,其运动周期受到其他天体影响过于巨大,对于这样的天体再纳入训练只会起到反面作用。
- 可以通过计算数据的 残差 ,然后删除掉残差超过设定的 阈值 的数据,即噪声过大的数据来实现更精准的模型
代码
不经过对数处理
1 | import numpy as np |
经过对数处理
1 | import numpy as np |
结果
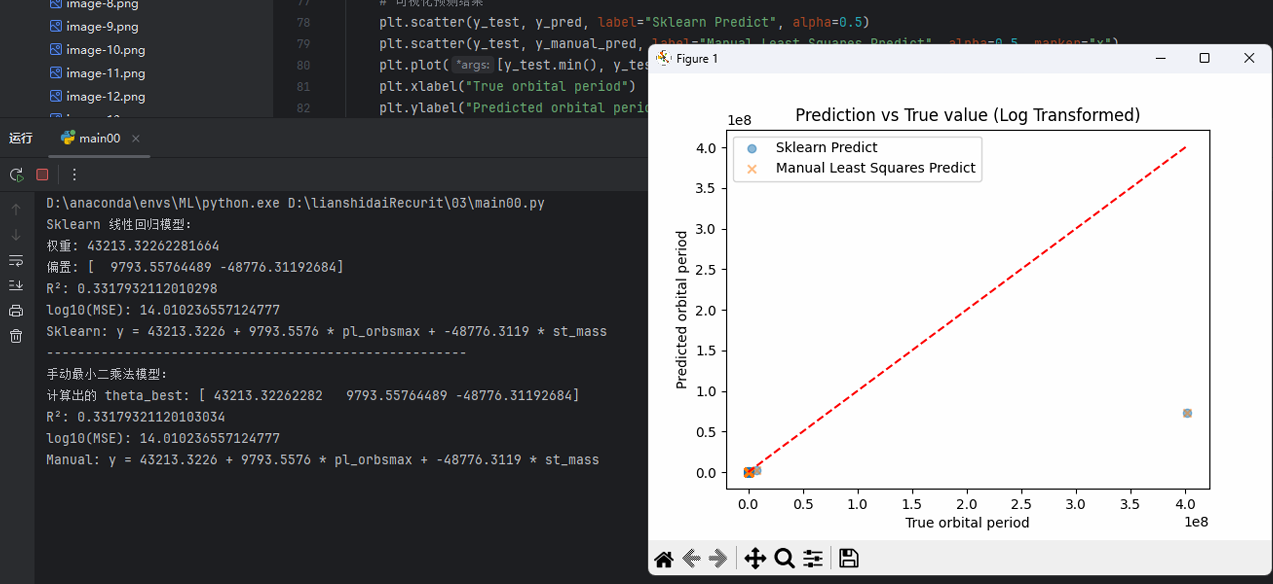
对数变化前:
对数变化后: